Gumbel-Max Trick
Gumbel-Max trick is a pretty interesting way of easily sampling from a pmf which is defined by the logits(and their softmaxed versions, individual probabilities). It also influenced subsequent research in deep learning which I will touch upon. The trick goes like this: Say you have logits at the final layer of a neural network and you want to convert those logits to probabilities - naturally, by softmaxing them- and want to sample from that resulting pmf. You can achieve this by adding Gumbel Noise to each logit and take the of the resulting vector.
- Add Gumbel noise to logits: For each alternative, draw a random number from a Gumbel distribution and add it to the corresponding logit:
-
Select the maximum: The alternative with the highest perturbed utility is selected:
This process guarantees that the choice is sampled according to the softmax probabilities:
Note that to implement the Gumbel-Max trick correctly, you should sample from the standard Gumbel distribution with location and scale
Proof
In this blog post, I go over the mathematical proof pretty rigorously. So here, I will do what I would normally do when I see this kind of stuff online: just verify it by code.
Suppose we have logits:
These logits correspond to following pmf when we softmax them:
I will implement the gumbel-max trick and verify that we are actually sampling from this pmf. Lets start by importing the required libraries and setting the seed.
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from scipy.special import softmax
# Set random seed for reproducibility
np.random.seed(42)
Lets implement three functions:
sample_gumbelcreates gumbel noise
def sample_gumbel(shape, eps=1e-20):
U = np.random.uniform(0, 1, shape)
return -np.log(-np.log(U + eps) + eps)
categorical_samplesamples from pmf:
def categorical_sample(probs, n_samples):
return np.random.choice(len(probs), size=n_samples, p=probs)
gumbel_max_sampleperforms the gumbel-max trick for the sampling
def gumbel_max_sample(logits, n_samples):
# Expand logits to match the number of samples
logits_expanded = np.tile(logits, (n_samples, 1))
# Generate Gumbel noise
gumbel_noise = sample_gumbel(logits_expanded.shape)
# Add noise to logits and get argmax
perturbed_logits = logits_expanded + gumbel_noise
samples = np.argmax(perturbed_logits, axis=1)
return samples
We can easily sample using both ways as fallows:
# Set parameters
logits = np.array([2.0, 0.5, 0.5, 1.0, 0.3])
n_samples = 10000
probs = softmax(logits)
# Generate samples using both methods
gumbel_samples = gumbel_max_sample(logits, n_samples)
categorical_samples = categorical_sample(probs, n_samples)
# Compute histograms
gumbel_hist = np.bincount(gumbel_samples, minlength=len(logits)) / n_samples
categorical_hist = np.bincount(categorical_samples, minlength=len(logits)) / n_samples
Here are the resulting histograms comparing both sampling methods:
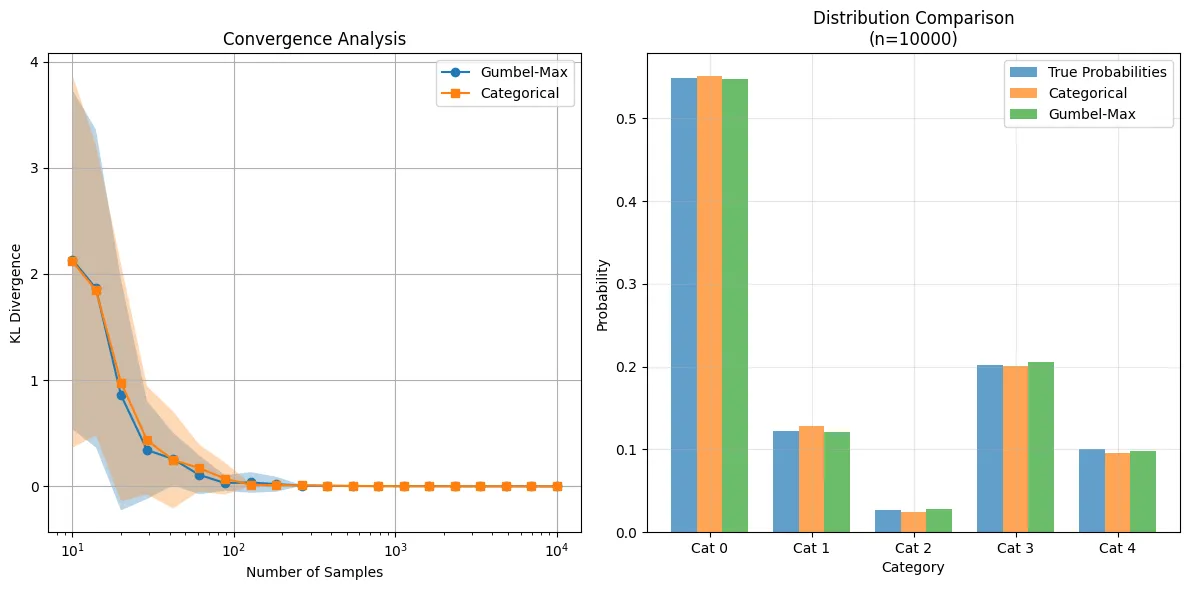
The notebook I use to plot the histograms are on my github
A* Sampling
The Gumbel-Max trick is also closely connected to A Sampling*, a method introduced in the paper titled “A* Sampling” by Maddison, Tarlow, and Minka (2014). In this paper, the authors propose a way to generalize the Gumbel-Max trick to handle sampling from continous distributions. They do so by, introducing the concept of a Gumbel process—a stochastic process where each point in a continuous domain is associated with a Gumbel random variable and by using A* search algorithms, they efficiently sample from complex continuous distributions.
This method has been instrumental in deep learning research, particularly in the development of the Gumbel-Softmax estimator (a.k.a. the Concrete distribution), which enables differentiable sampling from discrete distributions.
Extending to the Gumbel-Softmax Trick
I will extend the Gumbel-max trick to Gumbel-Softmax trick in another blog-post.